Construire la carte de vos flux de données pour réussir la migration de votre Data Warehouse vers le cloud
05/02/25 08:47
Lorsque vous prévoyez de migrer votre Data Warehouse (DWH) on-premise vers une solution cloud, il est essentiel d’avoir une vision claire de l’ensemble de vos flux de données. Autrement dit, il vous faut une carte (ou un schéma) qui représente précisément comment vos données sont chargées, transformées et utilisées. Bien souvent, ce plan n’existe pas – ou plus –, et c’est à vous de le créer. Dans cet article, nous allons voir pourquoi et comment construire cette fameuse carte, et en quoi un graphe ou réseau peut se révéler être un outil puissant pour vous aider dans cette démarche.
Un Data Warehouse (DWH) est un environnement dans lequel les données sont organisées de manière à servir au pilotage et à l’analyse business. On parle souvent de « version de la vérité » de l’entreprise, c’est-à-dire un référentiel unique et centralisé qui regroupe à la fois des données provenant :
Pour passer d’une couche à l’autre, on utilise des ETL (Extract, Transform, Load). Ces processus permettent :
Pour plus de détails sur la construction d’un ETL, voir notre article précédent.
Au fur et à mesure de ces transformations, on obtient progressivement des données de plus en plus prêtes à l’usage pour le business. Pour illustrer cela, imaginons des tables fictives nommées Z et W (issues de couches plus « brutes ») qui servent à construire une table A (couche intermédiaire). Et de la même manière, la table A s’associe à la table B pour construire la table C (couche finale, prête pour l’analyse).
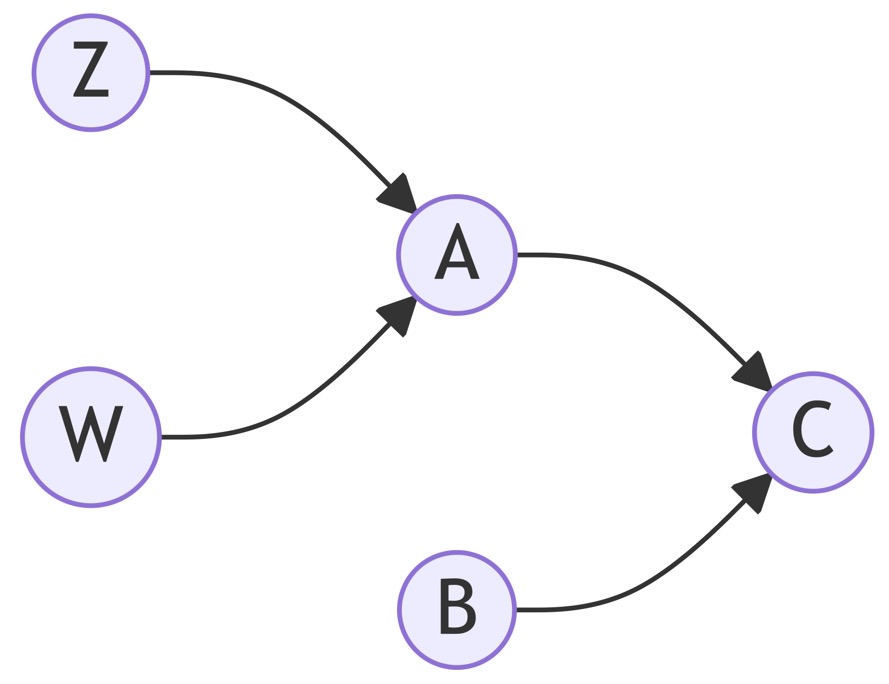
Visuellement, on peut imaginer trois couches de gauche à droite, avec les tables Z et W tout à gauche, la table A au milieu, et la table C tout à droite. La table B pourrait être dans la même couche que A, ou plus à gauche/droite, selon votre architecture.
Avant la migration vers le cloud, vous avez impérativement besoin de savoir :
Pour cartographier vos flux, vous pouvez commencer par analyser les scripts ETL. Dans un cas idéal, vos outils d’ETL ajoutent un header au début de chaque code, précisant :
Cela signifie :
À partir de ce tableau, vous pouvez construire un graph dont :
Une fois votre graph construit, vous pouvez :
Migrer un Data Warehouse on-premise vers le cloud est un chantier d’envergure, qui nécessite de la préparation et une bonne connaissance de son existant. En construisant une carte (ou documentation) des flux de données, puis en la modélisant sous forme de graph, vous vous donnez les moyens de :
Alors, avant de lancer votre migration, prenez le temps de documenter vos flux et de les cartographier. Vous gagnerez en sérénité, en efficacité et vous serez prêts à faire face à tous les défis du passage au cloud.
En résumé :
Aurélien Mairesse
1. Qu’est-ce qu’un Data Warehouse ?
Un Data Warehouse (DWH) est un environnement dans lequel les données sont organisées de manière à servir au pilotage et à l’analyse business. On parle souvent de « version de la vérité » de l’entreprise, c’est-à-dire un référentiel unique et centralisé qui regroupe à la fois des données provenant :
- Des systèmes opérationnels internes (ERP, CRM, systèmes métiers)
- De partenaires externes
- ODS : couche la plus proche des sources, contenant des données peu ou pas transformées.
- DWH : couche intermédiaire, où l’on commence à structurer et enrichir les données.
- DMA : couche la plus travaillée, la plus proche des besoins finaux, pour le reporting, l’analytics et le self-service BI.
2. Le rôle des ETL et la transformation des données
Pour passer d’une couche à l’autre, on utilise des ETL (Extract, Transform, Load). Ces processus permettent :
- D’extraire des données depuis leurs différentes sources.
- De transformer les données pour les nettoyer, les enrichir, les agréger.
- De charger enfin les données transformées dans la couche cible du Data Warehouse.
Pour plus de détails sur la construction d’un ETL, voir notre article précédent.
Au fur et à mesure de ces transformations, on obtient progressivement des données de plus en plus prêtes à l’usage pour le business. Pour illustrer cela, imaginons des tables fictives nommées Z et W (issues de couches plus « brutes ») qui servent à construire une table A (couche intermédiaire). Et de la même manière, la table A s’associe à la table B pour construire la table C (couche finale, prête pour l’analyse).
Visuellement, on peut imaginer trois couches de gauche à droite, avec les tables Z et W tout à gauche, la table A au milieu, et la table C tout à droite. La table B pourrait être dans la même couche que A, ou plus à gauche/droite, selon votre architecture.
3. Pourquoi construire une documentation et une « carte » des flux de données ?
Avant la migration vers le cloud, vous avez impérativement besoin de savoir :
- Quels sont les flux existants ?
- Quelles sont les interdépendances entre les tables ?
- Dans quel ordre sont chargées les données ?
- Analyser les impacts d’une modification ou d’un problème de qualité : par exemple, si une table source est affectée, quelles sont les conséquences sur les tables cibles et sur les rapports ?
- Planifier la migration et les tests de bout en bout : vous saurez dans quel ordre migrer et vérifier vos tables.
- Faciliter la maintenance : la carte sert de base pour comprendre rapidement les processus ETL et les parcours de données.
4. Construire un graph pour représenter vos flux
4.1 Extraire la liste des dépendances
Pour cartographier vos flux, vous pouvez commencer par analyser les scripts ETL. Dans un cas idéal, vos outils d’ETL ajoutent un header au début de chaque code, précisant :
- Les tables sources
- La table de destination
- A → C
- B → C
- Z → A
- W → A
Cela signifie :
- Pour construire C, on a besoin de A et B.
- Pour construire A, on a besoin de Z et W.
4.2 Modéliser ces dépendances sous forme de graph
À partir de ce tableau, vous pouvez construire un graph dont :
- Les noeuds sont vos tables (A, B, C, Z, W).
- Les arêtes (edges) sont les relations d’un ETL (la flèche de la table source vers la table destination).
- Un SGBD orienté graph comme Neo4j, qui excelle dans l’analyse de relations et la visualisation des interconnexions.
- Un langage comme R ou Python, via des librairies spécialisées (par ex. igraph, NetworkX), pour faire des analyses de graph ou réseau plus poussées.
5. À quoi sert concrètement ce graph ?
Une fois votre graph construit, vous pouvez :
- Visualiser rapidement l’ampleur des flux et l’enchaînement des transformations.
- Identifier l’ordre de migration : certaines tables doivent être migrées avant d’autres, car elles en sont la source.
- Analyser les impacts en cas de problème de qualité sur une table source. Par exemple, si la table A est corrompue, vous savez immédiatement que C sera impactée. Inversement, vous pouvez retrouver l’origine d’une anomalie sur A en remontant aux tables Z et W et à l’ETL correspondant.
- Planifier les tests : tester en priorité les tables critiques ou dont dépendent de nombreuses autres tables.
- Définir la roadmap de la migration.
- Anticiper les risques.
- Faciliter la communication entre équipes (IT, business, Data Ops, etc.).
6. Conclusion : la documentation comme fondation de la réussite
Migrer un Data Warehouse on-premise vers le cloud est un chantier d’envergure, qui nécessite de la préparation et une bonne connaissance de son existant. En construisant une carte (ou documentation) des flux de données, puis en la modélisant sous forme de graph, vous vous donnez les moyens de :
- Maîtriser l’ensemble de vos processus ETL.
- Identifier les dépendances et priorités de migration.
- Anticiper les impacts et faciliter la résolution des problèmes.
Alors, avant de lancer votre migration, prenez le temps de documenter vos flux et de les cartographier. Vous gagnerez en sérénité, en efficacité et vous serez prêts à faire face à tous les défis du passage au cloud.
En résumé :
- Un DWH est le socle de la vérité business.
- Les ETL permettent de transformer et d’enrichir les données entre les couches.
- Construire une documentation et un graphe de dépendances (tables / ETLs) est la meilleure façon de réussir votre migration.
- Cette carte vous permettra une analyse d’impact efficace et facilitera votre plan de test.
Aurélien Mairesse